|
2025.03
|
Recent achievements of the team - Deep Learning-Based Framework for Efficient Design of Multicomponent High Hardness High Entropy Alloys
|
|
Our team published the paper “Deep Learning-Based Framework for Efficient Design of Multicomponent High Hardness High Entropy Alloys” in the journal ACS Applied Materials & Interfaces (IF: 8.3, CAS Region II). The School of Computer Engineering and Science of Shanghai University is the first department of the paper, with Yuexing Han as the first author, Hui Wang as the second author, and Yi Liu as the corresponding author.
|
|
In the field of materials science, high-entropy alloys (HEAs) have become a research hotspot due to their excellent properties. However, finding an optimal design that is both innovative and reliable in the vast alloy composition space poses a huge challenge. Traditional trial-and-error methods are inefficient, while purely data-driven approaches struggle to ensure the practical performance of designs. To address this issue, we propose a deep learning-based framework that combines domain knowledge in materials science with data-driven techniques to optimize the design process of multicomponent high-hardness high-entropy alloys.
|
|
![]()
|
|
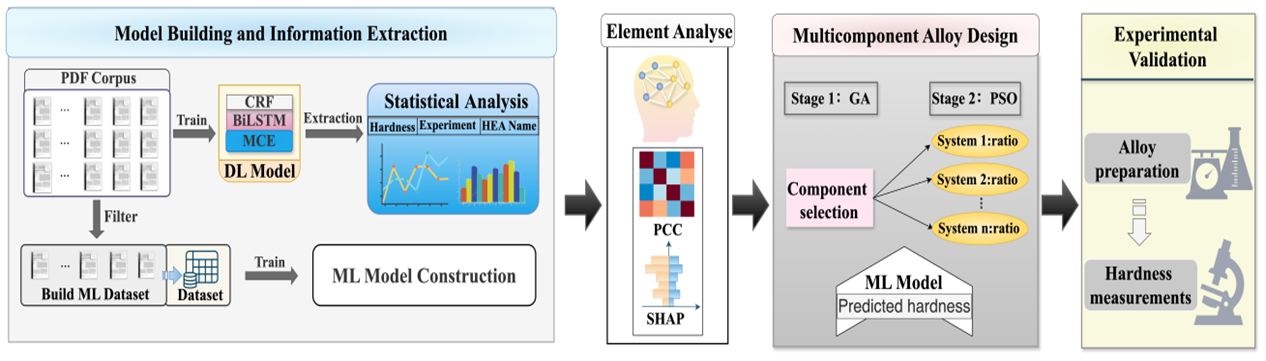
First, we developed a Materials Cascade Embedding (MCE) module and integrated it with the BiLSTM-CRF network (MCE-BILSTM-CRF) to automatically analyze 2,698 papers published in the past 5 years and extracted 8,067 data points. By incorporating materials domain knowledge into the data analysis, we identified high-potential elements and critical process conditions to guide the design and construction of machine learning datasets. After manually summarizing and organizing the target literature, we constructed a hardness dataset containing 13 elements. Based on this, we utilize a two-stage design strategy combining genetic algorithm (GA) and particle swarm optimization (PSO) to develop multi-component high-entropy alloys. The first stage explores the alloy system and the second stage optimizes the component ratios, thereby promoting innovation and performance enhancement. Our analysis combines SHAP feature significance and Pearson correlation coefficients (PCCs), complemented by materials domain knowledge, to validate the findings and guide the selection of alloy systems. In the end, we successfully designed three high-entropy alloys that differed from the existing dataset and predicted an average relative hardness error of less than 5%, with the optimal alloy being only 38 HV lower than the historical record.
|
|
|
2025.01
|
Recent achievements of the team - Fast and Accurate Recognition of Perovskite Fluorescent Anti-Counterfeiting Labels Based on Lightweight Convolutional Neural Networks
|
|
Our team published the paper “Fast and Accurate Recognition of Perovskite Fluorescent Anti-Counterfeiting Labels Based on Lightweight Convolutional Neural Networks” in the international journal ACS Applied Materials & Interfaces (IF:8.3, CAS Region II). Counterfeiting Labels Based on Lightweight Convolutional Neural Networks”. The School of Computer Engineering and Science of Shanghai University is the first department of the paper, with Yuexing Han as the first author, Shengqi Bao as the second author, Bozhi Shi as the third author, and Qiaochuan Chen as the corresponding author.
|
|
![]()
|
|
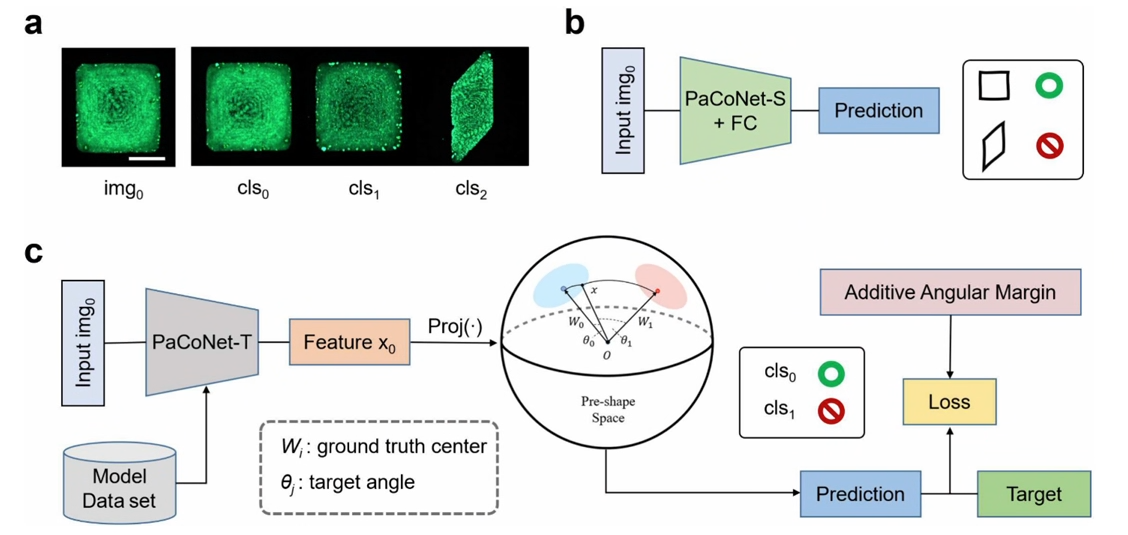
Anti-counterfeiting technology has always been a key issue in the field of information security. Physical unclonable function (PUF) labels, which are random patterns generated by a stochastic process, are an effective anti-counterfeiting strategy due to the inherent randomness of their physical patterns. In this study, a high-throughput droplet array generation technique based on surface tension constraints was developed for the preparation of chalcogenide crystal films with controllable shapes and sizes. The texture of PUF labels is constructed by utilizing the random distribution of chalcogenide nanocrystal grains. Compared with other anti-counterfeiting labels, the labels in this study not only have fluorescent properties, but also have micrometer size, low cost, and high encoding capacity, which provide support for multilevel anti-counterfeiting protection. In addition, this study introduces an innovative PUF recognition method based on Partial Convolutional Network (PaCoNet), which effectively addresses the limitations of previous methods in terms of recognition accuracy and speed. Experimental validation of a dataset of chalcocite nanocrystal films containing up to 60 different macro shapes and unique micro textures shows that the method in this study achieves recognition accuracy of up to 99.65% and significantly reduces the recognition time per image to only 0.177 seconds, highlighting the potential application of these tags in the field of anti-counterfeiting.
|
|
|
2025.01
|
Recent achievements of the team - Statistics and Analysis of Lath Martensite Transformation based on in-situ observation and video processing
|
|
Our team published the paper “Statistics and Analysis of Lath Martensite Transformation based on in-situ observation and video processing”. The School of Computer Engineering and Science, Shanghai University was the first department, Yuexing Han was the first author, Ruiqi Li was the second author, and Xiangyu Xu was the corresponding author.
|
|
Research methods in materials science are undergoing a new transformation with the development of artificial intelligence and scientific equipment. The shift from the traditional way of studying material properties based on static images to revealing the process of material microstructural changes through dynamic videos has not only enhanced the depth of research, but also dramatically improved the efficiency of data processing. Especially in the field of steel manufacturing, the study of the phase transition from austenite to martensite is crucial for optimizing material properties.
|
|
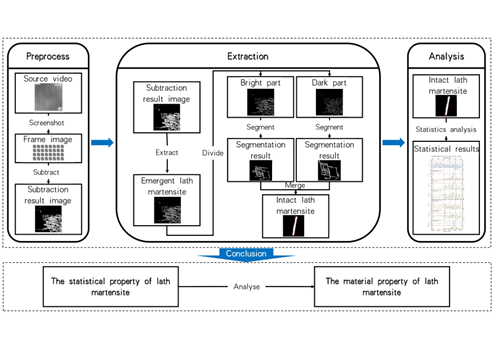
In this paper, we propose a dynamic video-based method for analyzing the phase transformation of slat martensite, which breaks through the limitations of static image research. The method can efficiently segment and extract the image data of individual slat martensite, and analyze its changing law in dynamic video. By counting several key attributes including the number, size, area and direction of the transformed slats, we realize a comprehensive analysis of the dynamic characteristics of martensite phase transformation. This method not only improves the information extraction efficiency, but also provides important data support for revealing the martensite phase transformation mechanism and optimizing the steel manufacturing process.
|
|
The results show that dynamic video studies can significantly improve the efficiency and accuracy of data processing, especially when facing the complex morphology and rapid transformation process of slat martensite. In the future, I would like to apply this method to the study of more material systems to further promote the optimization of material properties and process improvement.
|
|
|
2025.01
|
Recent achievements of the team - Automatic pipeline for information of curve graphs in papers based on deep learning
|
Our team published a paper "Automatic pipeline for information of curve graphs in papers based on deep learning" in the international journal 《International Journal of Machine Learning and Cybernetics》 (IF : 3.1, CAS Region III). The School of Computer Engineering and Science of Shanghai University was the first department, Yuexing Han is the first author, Jinhua Xia is the second author, and Qiaochuan Chen is the corresponding author.
|
|
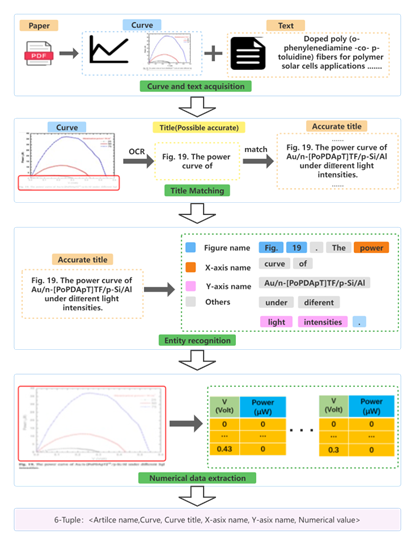
In materials science and biomedical fields. Current academic database tools mainly focus on mining textual information, ignoring the valuable information presented in graphs and charts. Extracting information from a large amount of literature can help researchers quickly grasp the current state of development. Literature is a carrier of many forms of data, and most researchers focus only on textual content. Especially, like graphs, they contain a lot of key numerical information that is not expressed in other data. In this paper, we propose a method for extracting information from graphs in the literature. With this method, the numerical values and axis entities of curved graphs can be extracted from both graphs and text. Firstly, the curved graphs are cut out from the literature using Yolov5s. Then, the exact title text corresponding to each curve graph is matched by manipulating Sentence-Bert. After obtaining the title text, the X-axis and Y-axis names in the curve graphs were extracted using SCI-Bert. At the same time, techniques such as Optical Character Recognition (OCR) were used to automatically parse the numerical data reflected on the graphs. In addition, a number of principles are used to improve performance. We validated each step using a dataset of 6042 articles from Elsevier. With our method, the accuracy of graph detection and title matching are 96.4% and 95.8% respectively, which are both better than the initial model, proving the effectiveness of our method. The accuracy of entity and numerical data extraction is 76.3% and 28.2%, respectively. The experimental results show that our method is able to achieve large-scale knowledge extraction of curve diagrams from the literature.
|
|
![]()
|
|
 English |
English |
 中文 |
中文 |