|
2025.03
|
团队近期成果--利用深度学习高效设计多组分高硬度高熵合金的框架
|
|
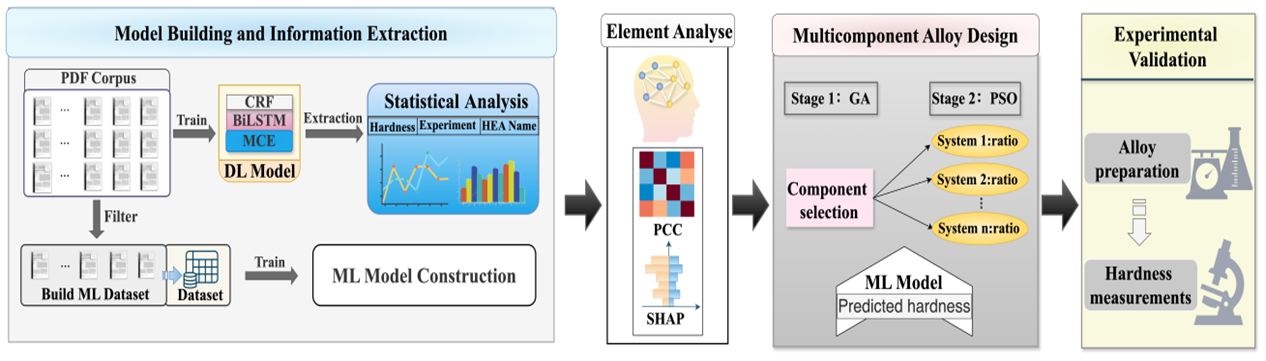
我们团队在《ACS Applied Materials & Interfaces》(IF: 8.3, 中科院二区)上发表论文“Deep Learning-Based Framework for Efficient Design of Multicomponent High Hardness High Entropy Alloys”。该论文上海大学计算机工程与科学学院为第一单位,韩越兴为第一作者,王慧为第二作者,刘轶为通讯作者。
|
|
在材料科学领域,高熵合金(HEAs)因其优异的性能而成为研究热点。 然而,在广阔的合金成分空间中寻找兼具创新性和可靠性的最优设计面临巨大挑战。 传统试错法效率低下,而单纯的数据驱动方法又难以保证设计的实用性能。 针对这一问题,我们提出了一种基于深度学习的框架,该框架将材料领域知识与数据驱动技术相结合,以优化多组分高硬度高熵合金的设计过程。
|
|
首先,我们开发了一个材料级联嵌入(MCE)模块,并将其与BiLSTM-CRF网络集成(MCE-BILSTM-CRF),自动分析了过去5年中发表的2698篇论文,提取了8067个数据点。 通过将材料领域知识融入数据分析,我们识别了高潜力元素和关键工艺条件,以指导机器学习数据集的设计和构建。 经过手动总结和整理目标文献,我们构建了一个包含13种元素的硬度数据集。 在此基础上,我们利用遗传算法(GA)和粒子群优化(PSO)相结合的两阶段设计策略来开发多组分高熵合金。 第一阶段探索合金体系,第二阶段优化成分比例,从而促进创新和性能提升。 我们的分析结合了SHAP特征重要性和皮尔逊相关系数(PCC),并辅以材料领域知识,以验证研究结果并指导合金系统的选择。最后,我们成功设计了三种不同于现有数据集的高熵合金且预测的平均相对硬度误差低于5%,最优合金的硬度仅比历史记录低38 HV。
|
|
|
2025.01
|
团队近期成果--基于轻量级卷积神经网络的钙钛矿荧光防伪标签快速准确识别技术
|
|
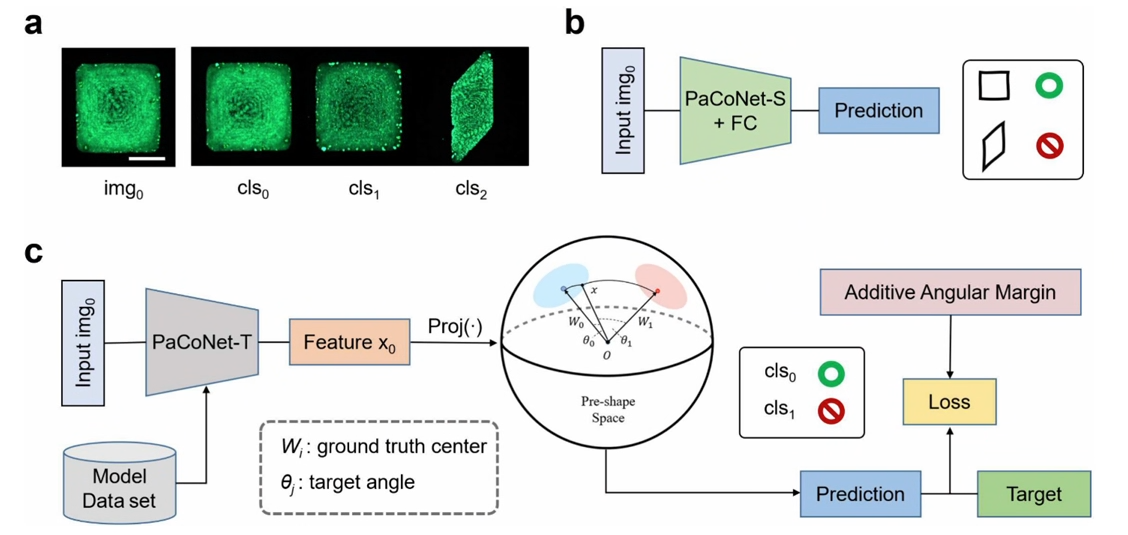
我们团队在国际期刊《ACS Applied Materials & Interfaces》(IF:8.3,中科院二区)上发表论文“Fast and Accurate Recognition of Perovskite Fluorescent Anti-Counterfeiting Labels Based on Lightweight Convolutional Neural Networks”。该论文上海大学计算机工程与科学学院为第一单位,韩越兴为第一作者,包胜奇为第二作者,石博日为第三作者,陈侨川为通讯作者。
|
|
防伪技术一直是信息安全领域的关键问题。物理不可克隆函数(PUF)标签是由随机过程生成的随机图案,因其物理图案的固有随机性而成为一种有效的防伪策略。本研究开发了一种基于表面张力约束的高通量液滴阵列生成技术,用于制备具有可控形状和尺寸的钙钛矿晶体薄膜。通过利用钙钛矿纳米晶粒子的随机分布来构建PUF标签的纹理。与其他防伪标签相比,本研究的标签不仅具有荧光特性,还具有微米级尺寸、低成本和高编码容量,为多级防伪保护提供支持。此外,本研究引入了一种基于部分卷积网络(PaCoNet)的创新PUF识别方法,有效解决了之前方法在识别精度和速度方面的局限性。对包含多达60种不同宏观形状和独特微观纹理的钙钛矿纳米晶体薄膜数据集的实验验证表明,本研究的方法实现了高达99.65%的识别精度,并将每张图像的识别时间显著缩短至仅0.177秒,突显了这些标签在防伪领域的潜在应用。
|
|
|
2025.01
|
团队近期成果--基于现场观测和视频处理的板条马氏体相变统计分析
|
|
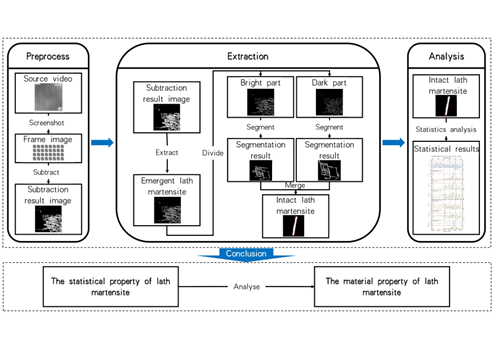
我们团队在国际期刊《Physics of Metals and Metallography》上发表论文“Statistics and Analysis of Lath Martensite Transformation based on in-situ observation and video processing”。该论文上海大学计算机工程与科学学院为第一单位,韩越兴为第一作者,李睿祺为第二作者,徐翔宇为通讯作者。
|
|
材料科学的研究方法正随着人工智能和科学设备的发展迎来新变革。从传统基于静态图像研究材料性能的方式,到通过动态视频揭示材料微结构变化过程,这一转变不仅提升了研究的深度,也大幅提高了数据处理的效率。尤其在钢材制造领域,研究奥氏体向马氏体的相变对优化材料性能至关重要。
|
|
本文中我们提出了一种基于动态视频的板条马氏体相变分析方法,突破了静态图像研究的局限性。该方法能够高效分割和提取单个板条马氏体的图像数据,并在动态视频中分析其变化规律。通过统计包括转变板条数量、尺寸、面积和方向在内的多个关键属性,我们实现了对马氏体相变动态特性的全面解析。这一方法不仅提高了信息提取效率,还为深入揭示马氏体相变机制和优化钢材制造工艺提供了重要数据支撑。
|
|
研究结果表明,动态视频研究能够显著提高数据处理的效率和精度,尤其在面对板条马氏体复杂形态和快速转变过程时。未来,我希望将这一方法应用于更多材料体系的研究,进一步推动材料性能优化与工艺改进。
|
|
|
2025.01
|
团队近期成果--利用深度学习从文献中提取曲线图信息的方法
|
|
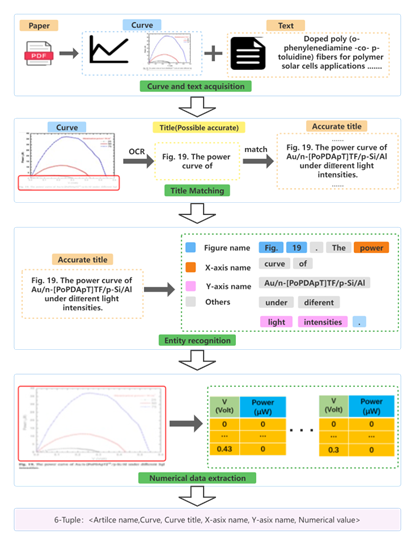
我们团队在《International Journal of Machine Learning and Cybernetics》(IF: 3.1, 中科院三区)上发表论文“Automatic pipeline for information of curve graphs in papers based on deep learning”。该论文上海大学计算机工程与科学学院为第一单位,韩越兴为第一作者,夏锦桦为第二作者,陈侨川为通讯作者。
|
|
在材料科学和生物医学领域。当前学术数据库工具主要集中在挖掘文本信息,而忽略了图表中所呈现的有价值的信息。从大量文献中提取信息可以帮助研究人员快速掌握当前的发展状态。文献是多种形式数据的载体,而大多数研究人员仅关注文本内容。尤其是像曲线图,包含了大量在其他数据中未表达的关键数值信息。本文提出了一种从文献中的曲线图提取信息的方法。通过该方法,可以从图形和文本中提取曲线图的数值和坐标轴实体。首先,使用Yolov5s从文献中剪切出曲线图。然后,通过操作Sentence-Bert来匹配与每个曲线图对应的准确标题文本。在获得标题文本后,使用SCI-Bert提取曲线图中的X轴和Y轴名称。同时,采用光学字符识别(OCR)等技术,自动解析图表上反映的数值数据。此外,还采用了一些原则来提高性能。我们使用来自Elsevier的6042篇文章的数据集验证了每个步骤。通过我们的方法,曲线图检测和标题匹配的准确率分别为96.4%和95.8%,均优于初始模型,证明了我们方法的有效性。实体和数值数据提取的准确率分别为76.3%和28.2%。实验结果表明,我们的方法能够实现从文献中大规模提取曲线图的知识。
|
|
 English |
English |
 中文 |
中文 |