|
2025.03
|
チームの最近の成果:深層学習に基づく多成分高硬度高エントロピー合金の効率的設計フレームワーク
|
|
私たちのチームは、論文 "Deep Learning-Based Framework for Efficient Design of Multicomponent 高硬度高エントロピー合金の効率的設計のためのディープラーニングに基づくフレームワーク」を発表した。 上海大学コンピューター工学科が筆頭著者となり、Yuexing Hanが第一著者、Hui Wangが第二著者、Yi Liuが対応著者となった。
|
|
材料科学の分野では、高エントロピー合金(HEA)がその優れた特性から注目の研究テーマとなっている。しかし、膨大な合金組成の中から革新性と信頼性を兼ね備えた最適設計を見出すことは、大きな課題に直面している。従来の試行錯誤的な手法は非効率的であり、純粋にデータ駆動的な手法では設計の実用的な性能を保証することは困難である。この問題に対処するために、我々は、多成分、高硬度、高エントロピー合金の設計プロセスを最適化するために、材料ドメインの知識とデータ駆動技術を組み合わせたディープラーニングベースのフレームワークを提案する。
|
|
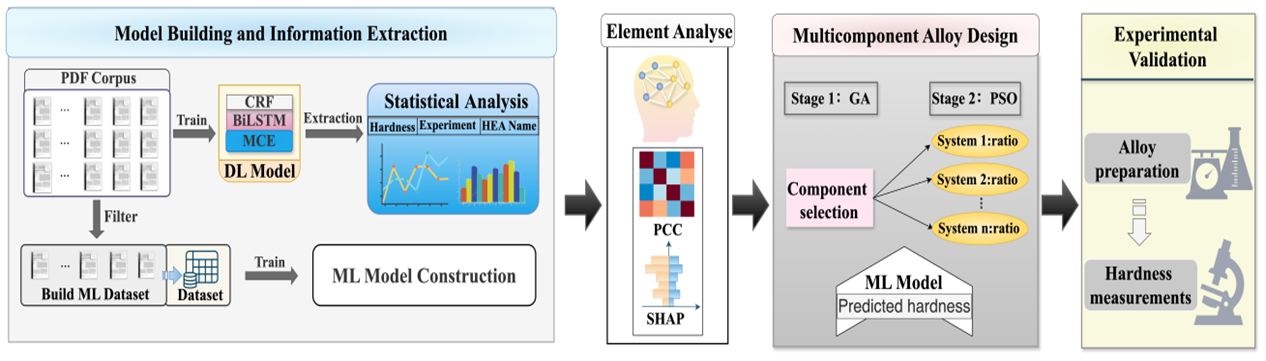
まず、Materials Cascade Embedding (MCE)モジュールを開発し、BiLSTM-CRFネットワーク(MCE-BILSTM-CRF)と統合して、過去5年間に発表された2,698の論文を自動的に分析し、8,067のデータポイントを抽出した。データ分析に材料分野の知識を取り入れることで、機械学習データセットの設計と構築の指針となる、可能性の高い要素と重要なプロセス条件を特定した。対象となる文献を手作業で要約・照合した後、13の要素を含む硬度データセットを構築した。これに基づいて、遺伝的アルゴリズム(GA)と粒子群最適化(PSO)を組み合わせた2段階の設計戦略を活用し、多成分の高エントロピー合金を開発した。第一段階では合金システムを探索し、第二段階では成分比率を最適化することで、技術革新と性能向上を促進する。我々の分析では、SHAP特徴の有意性とピアソン相関係数(PCC)を組み合わせ、材料分野の知識によって補完し、発見を検証して合金系の選択を導く。 最終的に、既存のデータセットとは異なる3種類の高エントロピー合金の設計に成功し、平均相対硬度誤差を5%未満に予測することができました。
|
|
|
2025.01
|
チームの最近の成果:軽量畳み込みニューラルネットワークに基づく方解石蛍光偽造防止ラベルの高速かつ正確な識別
|
|
論文「Fast and Accurate Recognition of Perovskite Fluorescent Anti-Counterfeiting Labels Based on Lightweight Convolutional Neural Networks」が国際学術誌ACS Applied Materials & Interfaces (IF:8.3, CAS Region II)に掲載されました。 軽量畳み込みニューラルネットワークに基づく偽造ラベル」。 この論文の筆頭著者は上海大学コンピューター工程科学学院、筆頭著者はYuexing Han、第2著者はShengqi Bao、第3著者はBozhi Shi、corresponding authorはQiaochuan Chenである。
|
|
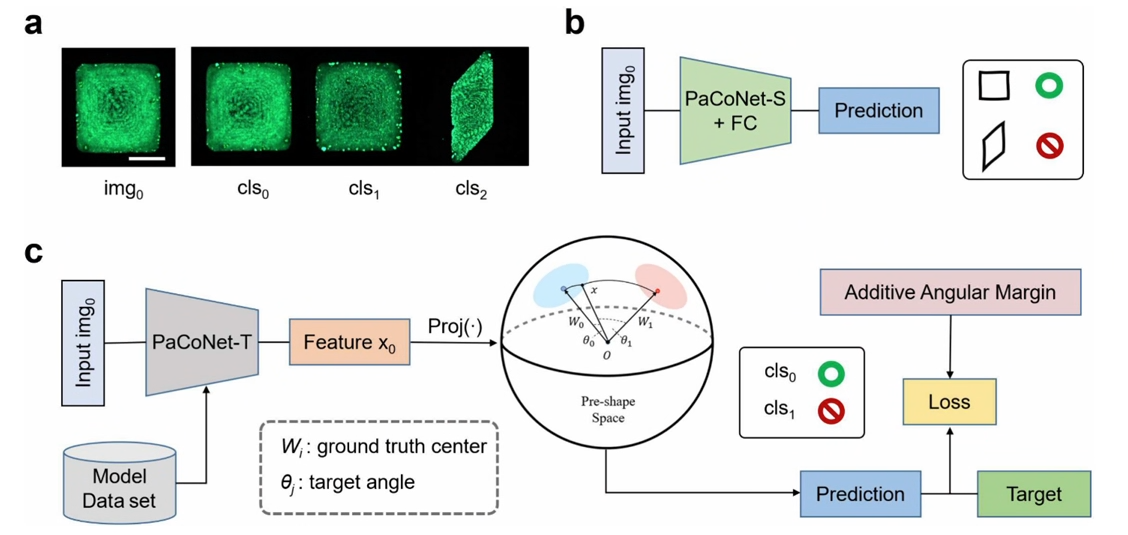
偽造防止技術は、情報セキュリティ分野において常に重要な課題である。 確率過程により生成されるランダムパターンであるPUF(Physical Unclonable Function)ラベルは、その物理パターン固有のランダム性により、偽造防止策として有効である。 本研究では、表面張力制約に基づく高スループット液滴アレイ生成技術を、制御可能な形状とサイズを有するカルコゲナイド結晶膜の調製のために開発した。 PUFラベルのテクスチャーは、カルコゲナイドナノ結晶粒のランダムな分布を利用して構築される。 他の偽造防止ラベルと比較して、本研究のラベルは蛍光特性を有するだけでなく、マイクロメートルサイズ、低コスト、高符号化能力を有し、多段階の偽造防止をサポートする。 さらに、本研究では、部分畳み込みネットワーク(PaCoNet)に基づく革新的なPUF認識手法を導入し、認識精度と速度の面で従来の手法の限界に効果的に対処している。 最大60種類の異なるマクロ形状とユニークなマイクロテクスチャを含むカルコサイトナノ結晶フィルムのデータセットを実験的に検証した結果、本研究の手法は最大99.65%の認識精度を達成し、画像1枚あたりの認識時間をわずか0.177秒に大幅に短縮することができ、偽造防止分野におけるこれらのタグの応用の可能性を浮き彫りにした。
|
|
|
2025.01
|
チームの最近の成果:その場観察とビデオ処理に基づくスラットマルテンサイト相変態の統計解析
|
|
私たちのチームは、論文「その場観察に基づくラスマルテンサイト変態の統計と解析」を発表した。Statistics and Analysis of Lath Martensite Transformation based on in situ observation and video processing "という論文を発表した。 筆頭著者は上海大学コンピューター工程科学学院、筆頭著者はYuexing Han、筆頭著者はRuiqi Li、筆頭著者はXiangyu Xuである。
|
|
材料科学における研究手法は、人工知能や科学機器の発達に伴い、新たな変革を遂げつつある。 従来の静止画像に基づく材料特性の研究方法から、動的な動画によって材料の微細構造が変化する過程を明らかにする方法への転換は、研究の奥行きを深めただけでなく、データ処理の効率も飛躍的に向上させた。 特に鉄鋼製造の分野では、オーステナイトからマルテンサイトへの相転移の研究は、材料特性を最適化するために極めて重要である。
|
|
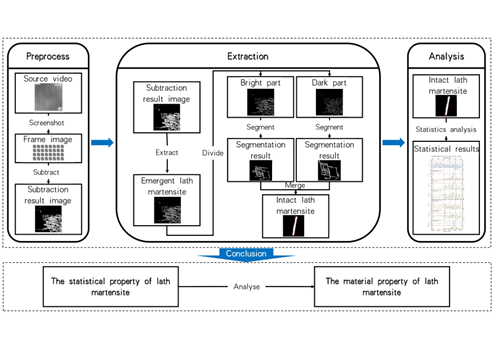
本論文では、静的画像研究の限界を打破する、動的動画を用いたスラットマルテンサイトの相変態解析法を提案する。 本手法は、個々のスラットマルテンサイトの画像データを効率的に分割・抽出し、その変化法則を動的動画で解析することができる。 変形したスラットの数、大きさ、面積、方向を含むいくつかの重要な属性をカウントすることにより、マルテンサイト相変態の動的特性の包括的な分析を達成する。 この方法は、情報抽出効率を向上させるだけでなく、マルテンサイト相変態メカニズムを明らかにし、鉄鋼製造プロセスを最適化するための重要なデータサポートを提供します。
|
|
この結果は、特にスラットマルテンサイトの複雑な形態と急速な変態過程に直面した場合、動的ビデオ研究がデータ処理の効率と精度を大幅に改善できることを示している。 将来的には、この方法をより多くの材料系の研究に応用し、材料特性の最適化とプロセス改善をさらに推進したいと考えています。
|
|
|
2025.01
|
チームの最近の成果: ディープラーニングを用いた文献からのグラフ情報抽出手法
|
私たちのチームは、論文 「Automatic pipeline for information of curve graph in papers based on deep learning 」を発表した。自動パイプライン」を発表した。 筆頭著者は上海大学計算機工程科学院、筆頭著者はYuexing Han、第2著者はJinhua Xia、corresponding authorはQiaochuan Chenである。
|
|
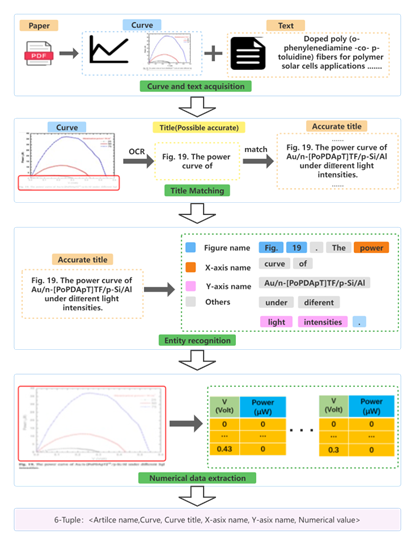
材料科学や生物医学の分野である。 現在の学術データベースツールは、主にテキスト情報のマイニングに重点を置いており、グラフやチャートに示された貴重な情報は無視されている。 大量の文献から情報を抽出することで、研究者は開発の現状を迅速に把握することができる。 文献は様々な形式のデータの担い手であり、ほとんどの研究者はテキストコンテンツにのみ注目している。 特にグラフのように、他のデータでは表現されない重要な数値情報が多く含まれている。 本稿では、文献中のグラフから情報を抽出する手法を提案する。 この手法では、グラフとテキストの両方から、曲線グラフの数値と軸実体を抽出することができる。 まず、Yolov5sを用いて文献から曲線グラフを切り出す。 次に、Sentence-Bertを操作して、各曲線グラフに対応する正確なタイトルテキストを照合する。 タイトルテキストを得た後、SCI-Bertを用いて曲線グラフのX軸とY軸の名前を抽出した。 同時に、光学式文字認識(OCR)などの技術を使用して、グラフに反映された数値データを自動的に解析した。 さらに、パフォーマンスを向上させるために多くの原則が用いられている。 Elsevierの6042の論文からなるデータセットを用いて、各ステップを検証した。 本手法を用いた場合、グラフ検出の精度は96.4%、タイトルマッチングの精度は95.8%であり、いずれも初期モデルを上回り、本手法の有効性が証明された。 エンティティの抽出精度は76.3%、数値データの抽出精度は28.2%であった。 実験結果から、本手法が文献から曲線図の大規模な知識抽出を実現できることが示された。
DeepL.com(無料版)で翻訳しました。
|
|
 English |
English |
 中文 |
中文 |