


Ma Weiyi graduated from Shandong University of Technology and began her professional master’s degree in the School of Computer Engineering and Science at Shanghai University in 2023. After joining the research group, she studied computer vision under the guidance of Professor Yang Fenglei, Professor Han Yuexing, and Professor Chen Qiaochuan. With their careful guidance, she completed the following research:
-
To address the weak multi-scale feature representation and continuous semantic attenuation in hierarchical fusion during field plant leaf disease detection, the HRAGNet detection algorithm is proposed. An interactive enhancement module is designed to achieve bidirectional recursive enhancement of cross-level features, a cross-scale semantic alignment module is used to correct feature spatial misalignment, and a global context aggregation and fusion module integrates multi-scale global information, effectively improving the feature discrimination ability for disease spots of different sizes in complex scenes.
-
To address the limitations of HRAGNet in the decoding stage, including the lack of spatial priors for disease spots and conflicts caused by feature coupling between classification and regression tasks, an improved algorithm, HRAGNet+, is proposed, constructing a geometry-task collaborative enhanced decoder. A geometric prior enhancement attention module is designed to explicitly model the spatial distribution relationships among disease spots. A task feature decoupling and fusion module is also built to adaptively separate classification-specific and regression-specific features, alleviating interference in multi-task optimization and significantly improving the localization and classification accuracy of tiny and dense disease spots.
-
Multiple public agricultural vision datasets, including PlantDoc, TLD, and FD, are selected for comparative experiments and ablation studies. Through multiple quantitative metrics, visualized samples, and robustness tests under extreme lighting conditions, the comprehensive performance of the two models is verified, fully demonstrating the effectiveness and generalization ability of multi-scale feature enhancement and geometry-task collaborative optimization mechanisms in leaf disease detection tasks.
-
After graduation, Ma Weiyi joined ByteDance in Beijing and will work in product operations. During her postgraduate studies at Shanghai University, Ma Weiyi studied diligently, kept improving, and continuously enhanced her professional and research capabilities. She was fortunate to work alongside many excellent mentors and friends and gained a great deal along the way. We hope that in her future journey she will always keep her ideals in mind, stay grounded, fear no hardship, and move forward bravely.
Essay: Research on Plant Leaf Disease Detection Methods Based on Multi-Scale Feature Enhancement and Fusion
Code: https://github.com/han-yuexing/2026-thesis-mwy-code

Shen Xinyu graduated from Shanghai Normal University and began his master’s degree in the School of Computer Engineering and Science at Shanghai University in 2023. After joining the research group, he studied the intersection of computer vision and smart agriculture under the guidance of Professor Sun Yan, Professor Han Yuexing, and Professor Chen Qiaochuan, focusing on weed detection in complex farmlands. With their careful guidance, he completed the following research:
-
To address the weak feature representation ability and susceptibility to background interference of existing weed detection methods in complex farmlands, an FS-DETR dual-domain fusion Transformer detection model is proposed. Through joint modeling of spatial-domain and frequency-domain attention, the model effectively enhances fine-grained feature representation in farmland images, accurately distinguishes crops and weeds with similar appearances, and further combines a constraint-guided label assignment strategy to optimize sample matching, greatly improving detection accuracy and training stability in complex field scenes.
-
To address the single decoder modeling and unstable predictions in dense occlusion scenes of existing Transformer detection algorithms, an enhanced decoder version, FS-DETR-D, is proposed. The method introduces dynamic query assignment and hyperedge higher-order query interaction mechanisms to adaptively handle complex farmland scenes with varying sparsity and occlusion, and accurately models the spatial structure of dense weed targets. At the same time, an adaptive perceptual loss function is designed to dynamically adjust supervision strength, effectively solving the pain points of missed detections, false detections, and large prediction fluctuations in traditional methods, and significantly improving the stability and prediction consistency of the decoding process.
-
To address the poor scene adaptability and limited generalization ability of existing farmland visual detection algorithms, a complete weed detection system with dual-domain fusion and decoding enhancement is built. Extensive experiments on multiple public datasets such as WeedCrop, LincolnBeet, and MH-Weed16 demonstrate that this system achieves better accuracy and robustness than mainstream detection methods, and the decoding-enhanced model achieves stable accuracy gains over the baseline model, effectively adapting to various real-world complex farmland operations and improving smart agriculture vision detection solutions.
After graduation, Shen Xinyu joined Honor Device Co., Ltd. and will work in software development and technology research and development. During his postgraduate studies at Shanghai University, Shen Xinyu studied diligently, kept improving, and continuously enhanced his professional and research capabilities. He was fortunate to work alongside many excellent mentors and friends and gained a great deal along the way. We hope that in his future journey he will always keep his ideals in mind, stay grounded, fear no hardship, and move forward bravely.
Essay: Research on Complex Farmland Weed Detection Methods Based on Transformers
Code: https://github.com/han-yuexing/2026-thesis-sxy-code

Li Ruijie graduated from Shanghai University and began his master’s degree in the School of Computer Engineering and Science at Shanghai University in September 2023. After joining the research group, he studied shape space theory, feature augmentation, and related technologies and applications under the guidance of Professor Han Yuexing. With Professor Han’s careful guidance, he completed the following research:
-
To address the challenges of poor optimization performance and low efficiency in existing iterative-search geodesic feature augmentation methods, an adaptive geodesic feature augmentation method based on shape space theory is proposed. This method overcomes the bottleneck that traditional linear interpolation in Euclidean space cannot capture the nonlinear geometric structure of features, aiming to generate high-quality features. Its core process is as follows: first, deep sample features are projected into pre-shape space, and adaptive geodesics are fitted for nonlinear feature augmentation; next, a joint loss function combining sample similarity loss and distribution discrepancy loss is redesigned to constrain the geodesic shape; finally, gradient descent replaces extensive point sampling and geodesic distance computation for optimization. Experiments show that, compared with existing methods, this method significantly improves augmented sample quality and downstream classification accuracy on few-shot datasets such as CIFAR-10@5, effectively reduces runtime and energy consumption, and demonstrates its potential in data-limited tasks.
-
To address the challenges of insufficient samples and difficulty fitting geodesics in extreme scenarios such as one-shot learning, a scalable geodesic feature augmentation framework is proposed. This framework aims to extend adaptive geodesic feature augmentation to scenarios ranging from one-shot learning to large-scale data, balancing computational efficiency and augmentation performance. Specifically, the framework introduces image-augmentation-driven feature expansion into the pre-shape-space feature augmentation process to alleviate feature scarcity in extreme scenarios, combines mini-batch gradient descent to handle large-scale data, and uses a sample-source-based weighting mechanism to balance the contributions of original and expanded features. Experiments show that the framework can achieve multi-scale feature augmentation without retraining the backbone network and, when generating augmented features, better preserve the distribution structure and discriminative ability of the original samples than comparison methods.
After graduation, Li Ruijie will join EA CHINA. Looking back on his three years at Shanghai University, he studied diligently, conducted research seriously, continuously improved his professional abilities, and built deep friendships with many mentors and friends. We hope Li Ruijie will carry these gains and experiences forward, keep his original aspiration, forge ahead, ride the waves, and embrace a bright future.
Essay: Research on Feature Augmentation Methods Based on Shape Space Theory
Code: https://github.com/han-yuexing/2026-thesis-lrj-code

Xu Tianyang graduated from Changzhou University and began his academic master’s degree in the School of Computer Engineering and Science at Shanghai University in 2023. After joining the research group, he studied small object detection under the guidance of Professor Han Yuexing, Professor Chen Qiaochuan, and Professor Sun Yan. With their careful guidance, he completed the following research:
-
A high-precision object detection method based on implicit feature fusion and hybrid adaptive label assignment is proposed. To address the problem of detail loss in feature fusion, implicit feature fusion uses implicit neural representations to map multi-scale features to a unified resolution for fusion, effectively preserving the fine-grained features of small objects. To address the difficulty of balancing the quality and quantity of positive samples for small objects, the hybrid adaptive label assignment strategy combines IoU and receptive field distance to construct a hybrid metric score, and uses an adaptive mechanism to accurately mine high-quality positive samples.
-
A real-time object detection method based on a selective sparse encoder and scale-aware Query selection is proposed. To address the excessive computational cost of processing high-resolution feature maps in Transformer-based detection architectures, the selective sparse encoder uses a feature selection mechanism and linear self-attention to greatly reduce memory usage and computational complexity. To resolve the confidence disadvantage of small object features during the Query filtering stage, the scale-aware Query selection mechanism introduces a decay coefficient based on the feature downsampling stride, dynamically improving the model’s attention to small objects.
During his postgraduate studies at Shanghai University, Xu Tianyang studied diligently, kept improving, and continuously enhanced his professional and research capabilities. He was fortunate to work alongside many excellent mentors and friends and gained a great deal along the way. We hope that in his future journey he will always keep his ideals in mind, stay grounded, fear no hardship, and move forward bravely.
Essay: Research on Real-Time Object Detection Methods for Small Objects
Code: https://github.com/han-yuexing/2026-thesis-xty-code

Li Ziming graduated from Shandong Jianzhu University and began his master’s studies in the School of Computer Engineering and Science at Shanghai University in 2023. After joining the research group, he studied image processing and computer vision under the guidance of Professor Zhang Rui, Professor Han Yuexing, Professor Chen Qiaochuan, and Professor Sun Yan. With their careful guidance, he completed the following research:
-
To address the needs of medical image scenarios, including insufficient learning of shape information, difficulty in coordinating local texture characterization with global structure modeling, and enhanced discrimination in complex boundary regions, a scribble-supervised segmentation method based on consistency constraints and contrastive learning is proposed. This method constructs a heterogeneous dual-branch network composed of different architectures to enhance the complementarity between local texture characterization and global structure modeling. It further combines a consistency learning mechanism based on network perturbation and input perturbation to generate more stable pixel-level pseudo-labels. Finally, foreground prototypes are used as anchors for pixel-level prototype contrastive calibration, thereby enhancing feature discrimination in complex boundary regions.
-
To address the needs of material microscopy image scenarios, including training stability under extremely small sample conditions, pseudo-label reliability, and boundary noise control near complex phase boundaries, a scribble-supervised segmentation method based on multi-history voting and boundary-aware constraints is proposed. This method combines transfer learning strategies of pre-trained initialization, shallow-layer freezing, and deep-layer fine-tuning to improve training stability under extremely small sample conditions. Meanwhile, through a historical prediction queue maintained for each sample, reliable pseudo-labels are selected by integrating multi-history voting and confidence estimation, improving the stability of pseudo-supervision from the temporal dimension. Furthermore, boundary smoothing and boundary sharpening constraints are jointly introduced during network optimization to enhance the model’s ability to characterize complex phase boundaries.
During his postgraduate studies at Shanghai University, Li Ziming studied diligently, kept improving, and continuously enhanced his professional and research capabilities. He was fortunate to work alongside many excellent mentors and friends and gained a great deal along the way. We hope that in his future journey he will always keep his ideals in mind, stay grounded, fear no hardship, and move forward bravely.
Code: https://github.com/han-yuexing/2026-thesis-lzm-code

Ge Jiaohao graduated from Shanghai University and began pursuing an academic master’s degree in the School of Computer Engineering and Science at Shanghai University in 2023. After joining the research group, he studied small-sample image processing and multi-task learning techniques and their applications in agriculture under the guidance of Professor Han Yuexing. With the careful guidance of Professor Han, he completed the following research:
-
To address the problem of multi-task feature interference and the difficulty of coordinating regression classification under small-sample conditions, a multi-task learning-based joint evaluation framework for multiple vegetable and fruit attributes is proposed. This method includes pre-classification routing, task branch modeling, feature enhancement and cross-branch interaction, and joint loss optimization. To support the training and evaluation of this method, the FruVegSet multi-attribute alignment dataset was further constructed, achieving one-to-one correspondence between images, continuous attributes, and grade labels based on weight, curvature, and maturity measurement results combined with grade mapping rules. Under the current data scale and experimental protocol, compared to single-task models and other multi-task models, this method achieves better comprehensive performance on cucumber and banana data, particularly showing stable performance in task balancing and grade discrimination.
-
To address the issue of missing transition states between endpoint samples under small-sample conditions for continuous attributes, a multi-task extension learning method based on intermediate sample generation is further proposed on the basis of the multi-task joint evaluation framework. This method generates intermediate transition samples through DiffMorpher, and combines the SAM2 segmentation model, subject mask screening strategy, and task-specific pseudo-label construction to improve the quality of supplementary supervision. Under the effect of this strategy, the method achieves stable improvements in critical phenotype feature regression and grade classification tasks, and to some extent improves the overall performance of the three tasks.
During his graduate studies at Shanghai University, Ge Jiaohao worked hard to improve his professional level and research capabilities, and made many good friends and mentors. We hope that Ge Jiaohao will pursue his future path with ideals in his heart, fear no hardship, and move forward bravely.
Code: https://github.com/han-yuexing/2026-thesis-gjh-code

Huang Zhiyi graduated from Capital Normal University and began her academic master’s degree in the School of Computer Engineering and Science at Shanghai University in 2023. After joining the research group, she studied agricultural object detection technologies and applications under the guidance of Professor Han Yuexing, Professor Chen Qiaochuan, and other teachers. With their careful guidance, she completed the following research:
-
To address the difficulty of locating and detecting multi-scale, occluded, and dense fruits with existing models in complex agricultural scenes, an agricultural fruit object detection method based on collaborative attention and hierarchical self-distillation is proposed. Through a multi-scale feature fusion reweighting module, a collaborative attention decoder, and a hierarchical self-distillation strategy, the method effectively improves localization robustness for multi-scale, occluded, and overlapping targets in complex scenes. Experimental results show that the proposed method outperforms existing methods in both detection accuracy and stability under complex environments, providing an effective solution for automated fruit production and harvesting.
-
To address the insufficient feature diversity and model adaptability in agricultural fruit maturity detection, an agricultural fruit object detection method based on a dynamic sparse mixture-of-experts mechanism is designed. By introducing a high-frequency detail enhancement module, a dynamic sparse mixture-of-experts decoder, and load-balancing and expert-diversity loss functions, the method enhances the model’s adaptability to complex illumination and environmental changes while maintaining expert diversity. Experimental results show that this method can effectively improve the accurate recognition of fruits at different maturity stages.
After graduation, Huang Zhiyi joined SMIC. During her three years of master’s study at Shanghai University, Huang Zhiyi studied diligently and actively engaged in scientific research. In the face of difficulties, she always maintained an optimistic attitude and strong perseverance, demonstrating solid independent research ability and sharp innovative thinking. We hope Huang Zhiyi will keep her original aspiration, fear no storms, and move steadily toward a bright future.
Code: https://github.com/han-yuexing/2026-thesis-hzy-code

Our team published the paper “Automatic Segmentation and Recognition of the Microstructure of High-Strength Low-Alloy Steel” in Materials (CAS Zone 3, JCR Q2). This paper focuses on the automatic segmentation and recognition of the microstructure of high-strength low-alloy steel.
Metallographic microstructure analysis is important for revealing the rules of microstructural evolution in steel during heat treatment and mechanical processing. However, optical microscopy images commonly suffer from blurred grain boundaries, uneven grayscale distribution inside grains, and irregular grain morphology, which pose challenges to accurate microstructure analysis. To address these issues, this paper proposes an automated metallographic image processing method based on superpixels, named DPSS (Dual-Phase Steel Segmentation), with a focus on high-quality microstructure segmentation and subsequent recognition.
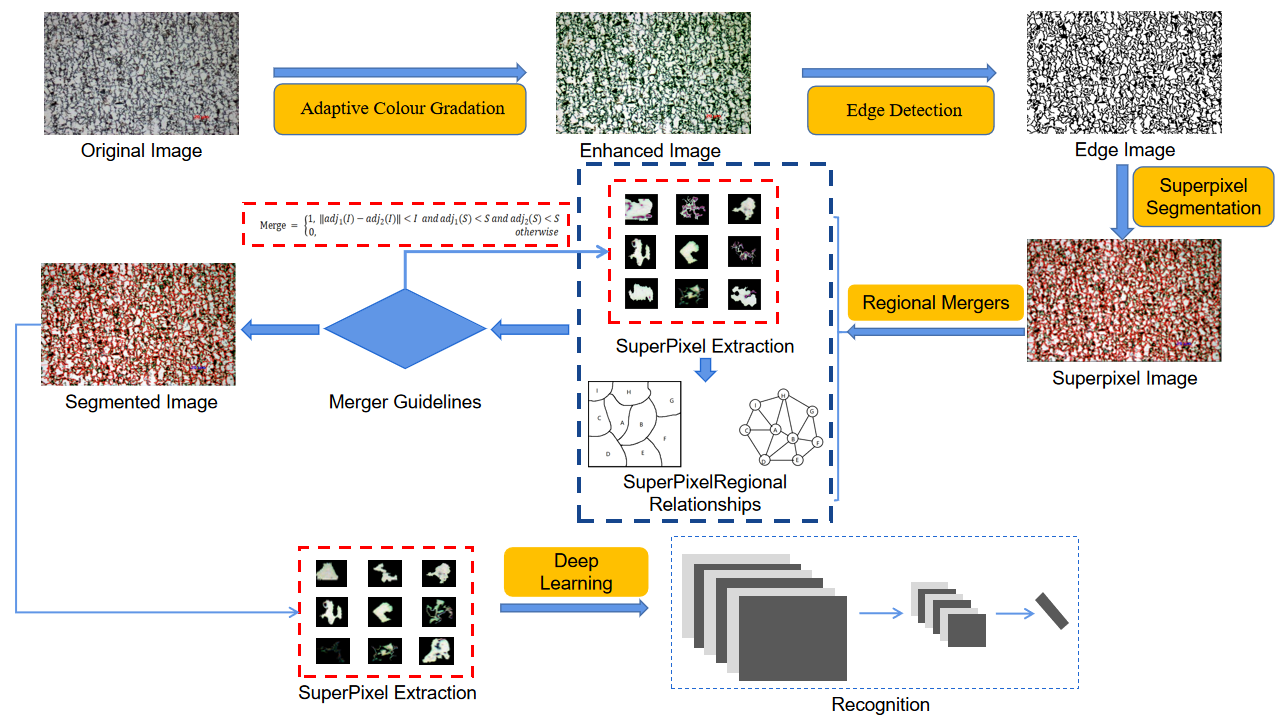
Specifically, DPSS first enhances image contrast and grain-boundary visibility through edge detection and image sharpening. It then combines superpixel segmentation with the extracted edge information to improve boundary localization accuracy while preserving irregular grain morphology, thereby achieving a more complete extraction of grain or particle regions in optical microscopy images. This paper verifies the method on optical microscopy images of Mn-Si low-alloy steel. Experimental results show that, compared with the traditional processing method based on ImageJ (Version 1.54f), DPSS obtains more accurate and complete microstructure segmentation results. On this basis, the paper further introduces a lightweight neural network for phase-structure recognition, ultimately achieving a classification accuracy of 99.91%. This result demonstrates that the improved segmentation method can provide more reliable input for subsequent microstructure recognition. Overall, the proposed method offers an efficient and automated solution for metallographic image segmentation and provides strong support for downstream phase-structure analysis.
Essay: Automatic Segmentation and Recognition of the Microstructure of High-Strength Low-Alloy Steel

Our team published the paper “Tiny object detection via implicit feature fusion and hybrid metric adaptive label assignment” in Knowledge-Based Systems (IF: 7.6, QSCI Zone 1 Top). The School of Computer Engineering and Science at Shanghai University is the first institution listed.
Tiny Object Detection (TOD) has broad applications in agricultural scenarios. Tiny objects contain extremely limited pixels, which restricts feature extraction and fusion and poses challenges to the label assignment strategies used in mainstream detection methods. To address these problems, this paper proposes a tiny object detection network based on Implicit Feature Fusion (IFF) and Hybrid Adaptive Label Assignment (HALA), named IHANet, aiming to achieve high-precision tiny object detection.
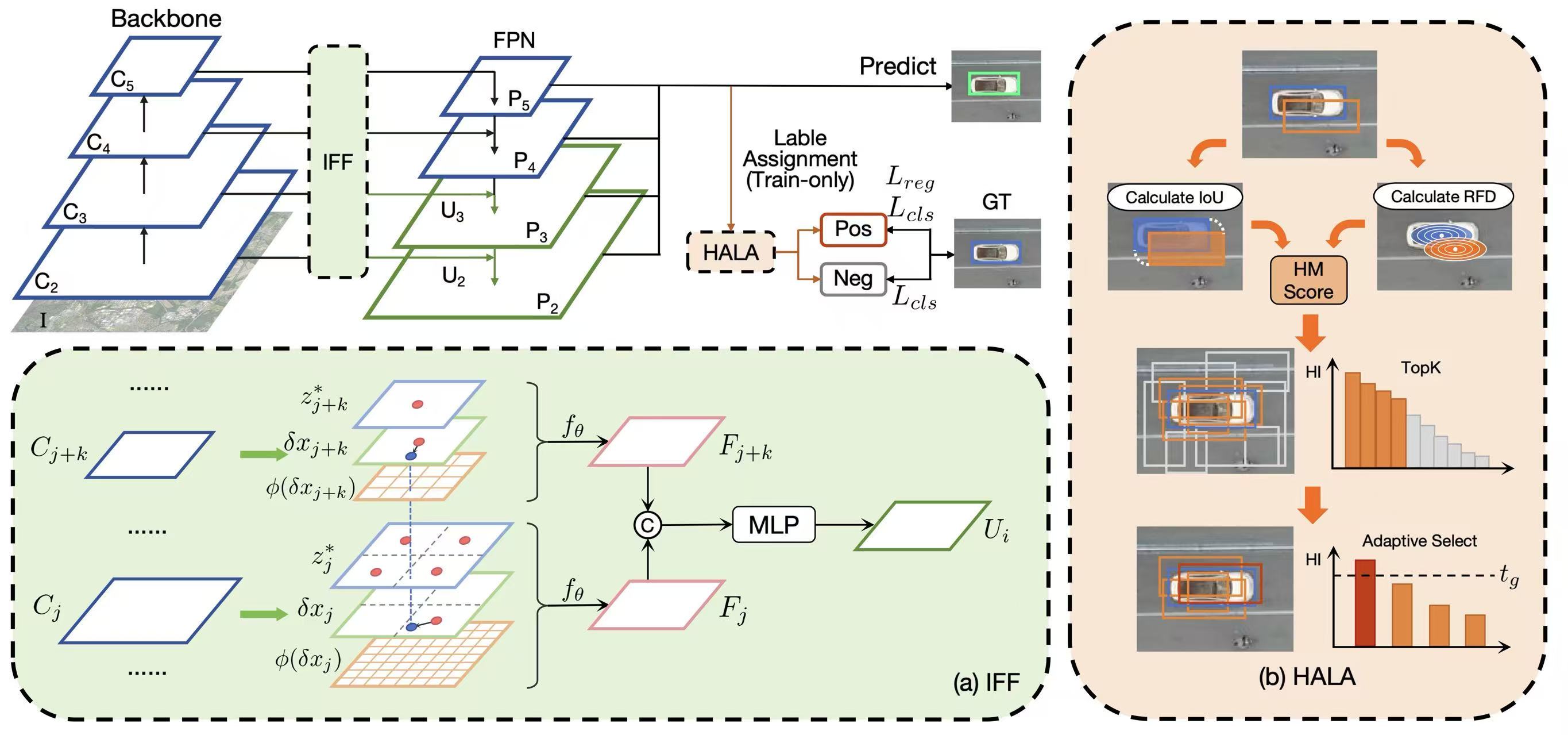
Specifically, IFF leverages implicit neural representations to alleviate feature misalignment in multi-scale fusion by mapping feature maps from different pyramid levels to a unified size before fusion. By modeling feature maps as continuous representations, IFF enables effective fusion at arbitrary resolutions, preserving tiny-object details and reducing information loss. HALA combines Intersection over Union (IoU) with Receptive Field Distance (RFD), which performs better in tiny object detection, and adopts an adaptive selection strategy to mine high-quality training samples. This optimizes the label assignment process and improves both training and detection performance. Extensive experiments on the AI-TOD, SODA-D, VisDrone, and AgriPest datasets show that IHANet achieves state-of-the-art performance across multiple TOD scenarios, reaching an AP of 29.1 on the AI-TOD dataset.
Essay: Tiny object detection via implicit feature fusion and hybrid metric adaptive label assignment
Code: https://github.com/han-yuexing/IHANet


Name: Ruan Liheng
Unit: Shanghai University
Topic: Research and Application of Few-Shot Image Generation Methods Based on Feature Enhancement with Shape Space Theory
Tutor: Prof. Han Yuexing

Our team published the paper “Deep learning-driven microstructure characterization and Vickers-hardness prediction of Mg-Gd alloys” in Journal of Magnesium and Alloys (QSCI Zone 1, JCR Q1). Taking high-strength Mg-Gd alloys as the research object, this paper focuses on quantitative modeling of the relationships among alloy processing, microstructure, and properties. It proposes a multimodal fusion framework based on image recognition and deep learning, enabling automated prediction of the Vickers hardness of Mg-Gd alloys.
In high-strength Mg-rare earth (Mg-RE) alloys, solution treatment and aging treatment significantly affect the microstructure and mechanical properties of the alloys. However, traditional experimental methods and physical modeling approaches still struggle to effectively establish quantitative mapping relationships among processing parameters, microstructural features, and property responses. To address this problem, this paper takes high-strength Mg-Gd alloys as a case study and constructs a quantitative analysis framework for “processing (solution and aging) - microstructure - properties”. Specifically, the mechanical properties of solution-treated Mg-Gd alloys are mainly influenced by Gd content, grain boundary characteristics, and the presence of second phases, while the properties of aged alloys are further jointly affected by Gd content, aging parameters, and precipitate features.
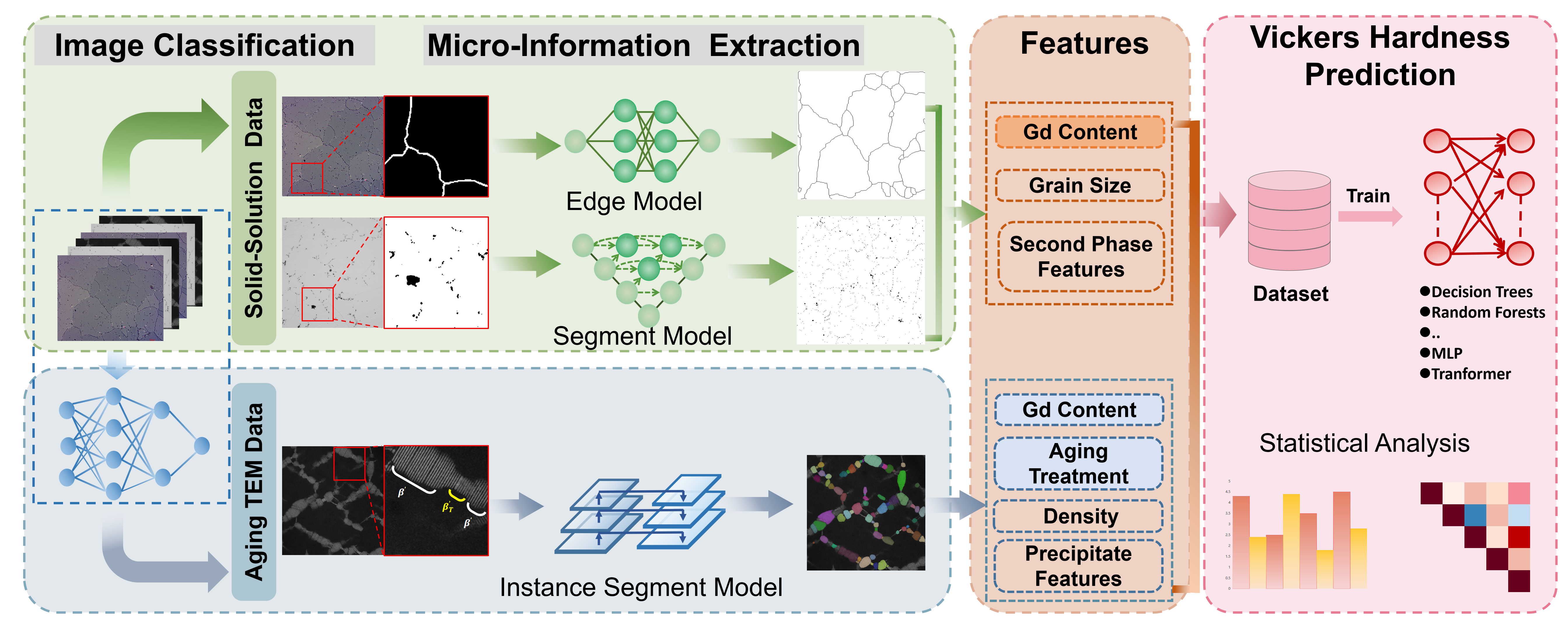
To establish the above mapping relationships, this paper proposes a two-stage multimodal fusion framework that combines elemental composition, processing parameters, and microstructural features extracted from alloy micrographs to predict alloy hardness. The framework first uses deep learning methods to automatically extract key microstructural features, such as grain size, second phases, and precipitates, from alloy images under different states. These image features are then fused with composition and processing parameters to construct solution-treated and aged datasets, respectively. The solution-treated dataset is used to predict solution-treated hardness, while the aged dataset is used to predict the hardness increment caused by aging treatment. Experimental results show that the two prediction models achieve R² values of 0.90 and 0.89, respectively, demonstrating high prediction accuracy.
Comparison with manual analysis results verifies that the proposed two-stage framework can automatically predict the final room-temperature hardness of Mg-Gd alloys, effectively reducing the cost of manual microstructure analysis.
Essay: Deep learning-driven microstructure characterization and Vickers-hardness prediction of Mg-Gd alloys
Code: https://github.com/han-yuexing/MCVHPA
Our team published the paper “Scribble consistency match and pixel-level prototype contrastive calibration for weakly supervised medical segmentation” in Neurocomputing (IF: 6.5, QSCI Zone 2). The School of Computer Engineering and Science at Shanghai University is the first institution listed. To address the high cost of pixel-level annotation for medical images and the insufficient supervision provided by scribble annotations, this paper proposes FW2SS, a weakly supervised medical image segmentation framework.
Medical image segmentation is an important task in medical image analysis. It is mainly used to accurately separate organs, tissues, or lesion regions from images such as CT and MRI, providing auxiliary support for disease diagnosis, quantitative analysis, and clinical treatment. In recent years, deep learning has significantly improved segmentation performance, but it usually relies on large amounts of precise pixel-level annotations. Since medical image annotation is costly and requires professional expertise, weakly supervised medical image segmentation has gradually become a research hotspot.
FW2SS is based on a CNN-Transformer hybrid architecture, combining the local detail modeling capability of CNNs with the global structural perception capability of Transformers. The paper proposes a Scribble Consistency Match technique, which generates more reliable dense pseudo-labels through consistency learning between network perturbations and input perturbations, enabling the model to learn complete shape information from sparse scribble annotations. Meanwhile, the Pixel-level Prototype Contrastive Calibration technique is introduced to construct category prototypes using high-confidence pixels and enhance intra-class consistency and inter-class discriminability through contrastive learning, thereby improving segmentation performance in boundary and detail regions.
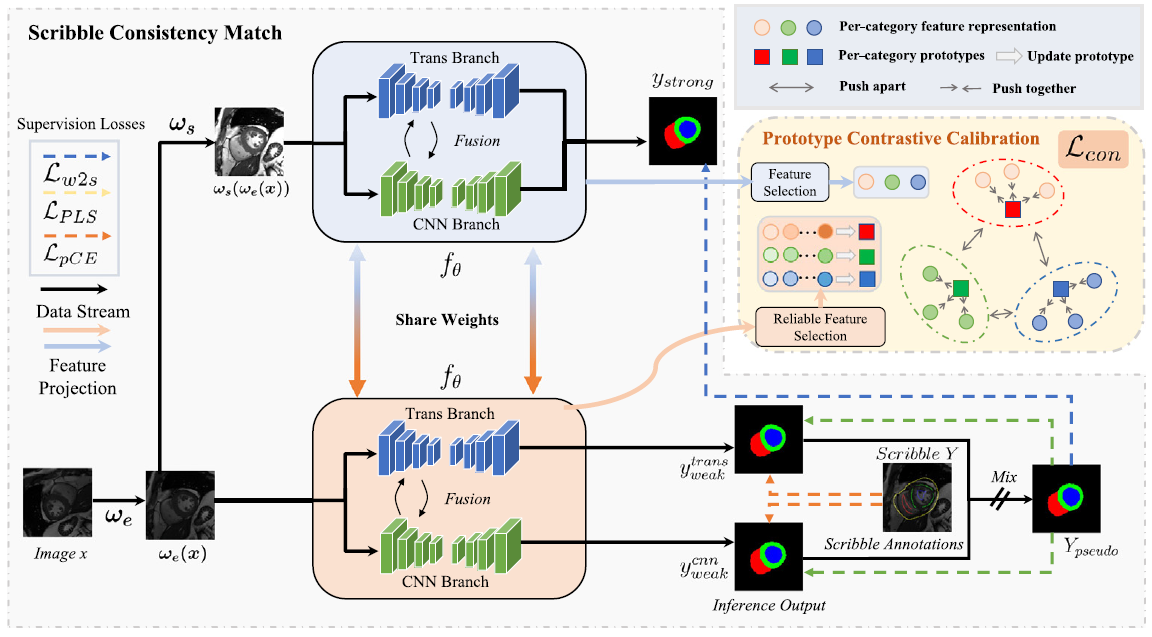
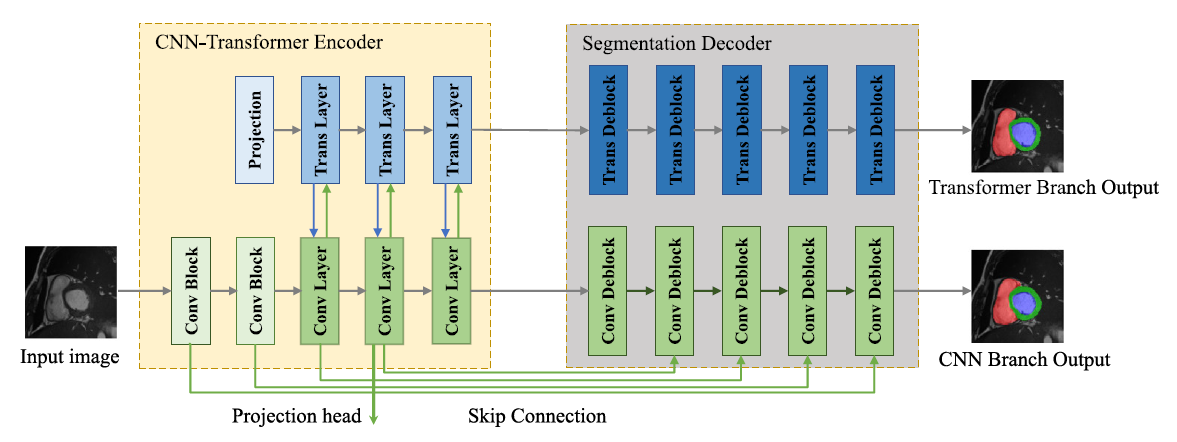
Experiments on the ACDC and MSCMRseg datasets show that FW2SS achieves state-of-the-art performance under scribble supervision, with average Dice scores of 90.0% and 88.2%, respectively, significantly outperforming various existing weakly supervised medical image segmentation methods. This research reduces the cost of medical image annotation while improving segmentation accuracy, providing an effective technical solution for weakly supervised medical image analysis and intelligent clinical assistance.
Code: https://github.com/han-yuexing/FW2SS

Our team published the paper “A multi-task learning framework for integrated assessment in agricultural applications” in Information Sciences (IF: 6.8, QSCI Zone 2). The School of Computer Engineering and Science at Shanghai University is the first institution listed.
Automated assessment of fruits and vegetables is an important task in smart agriculture, quality control, and supply chain management. Traditional manual weighing and visual inspection are time-consuming, labor-intensive, and highly subjective, while most existing automated methods focus on a single task and struggle to perform comprehensive multi-attribute assessment within a unified framework. In addition, datasets with multi-attribute annotations for fruits and vegetables remain limited. To address this problem, this paper proposes a multi-task deep learning framework for agricultural applications, capable of simultaneously performing weight prediction, key phenotypic feature analysis, and quality grade classification from a single RGB image.
Specifically, this paper constructs FruVegSet (FVS), an integrated assessment dataset for fruits and vegetables, covering two types of agricultural products, cucumbers and bananas, and providing multi-attribute annotations including images, weight, key phenotypic features, and quality grades. In terms of model design, this paper adopts a ResNet18-based pre-classification module to identify the category of agricultural products and route input images to corresponding category-specific subnetworks. Then, task-related features are extracted through the weight branch and key phenotype branch, respectively. A feature pyramid network is introduced to enhance morphological feature representation, while a large-kernel attention fusion module and cross-attention mechanism are combined to enable information interaction between tasks. Finally, the model simultaneously predicts weight, analyzes key phenotypic features, and classifies quality grades to complete integrated assessment. Experimental results show that the proposed framework achieves favorable integrated assessment performance on both cucumber and banana data, outperforming single-task models and representative agricultural quality classification models.
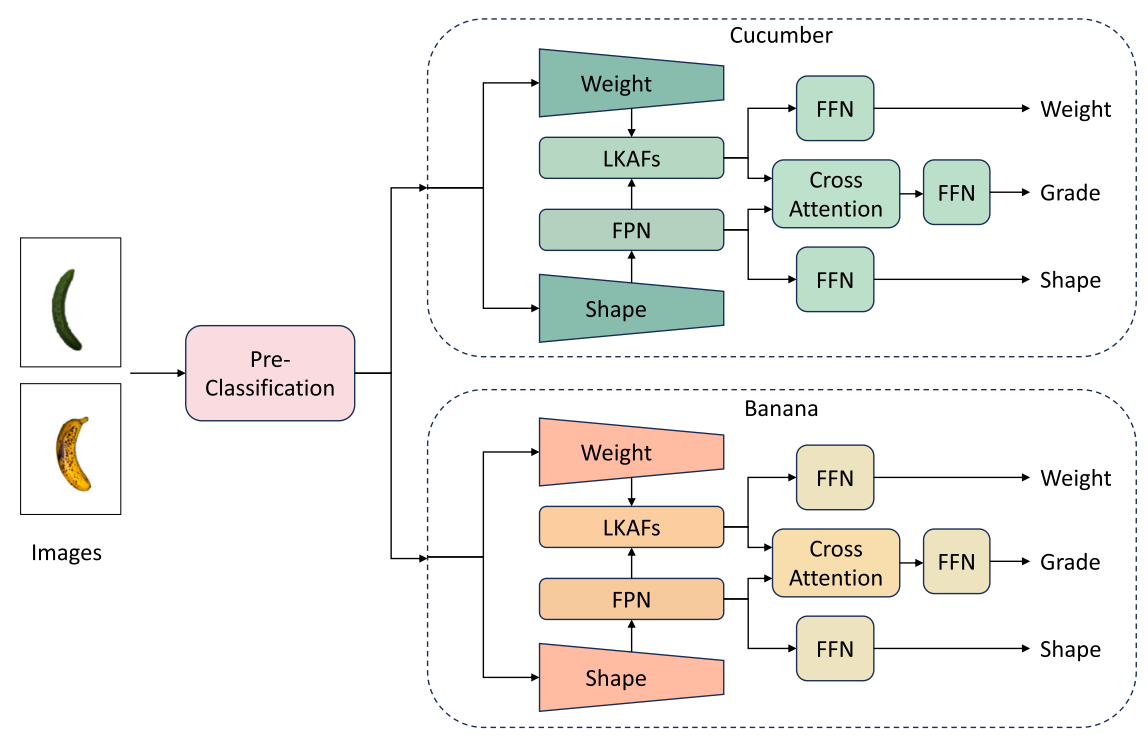
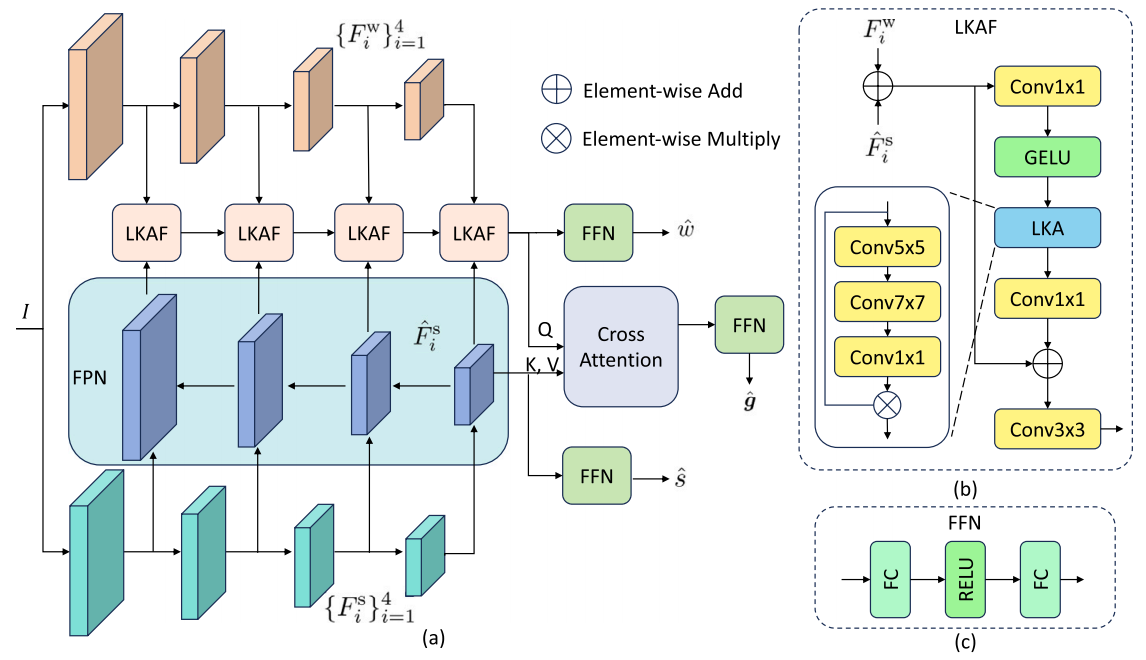
Essay: A multi-task learning framework for integrated assessment in agricultural applications

Our team published the paper “A Dual-Domain Detection Transformer for Fine-Grained Weed Detection in Complex Agricultural Scenes” in Information Sciences (IF: 6.8, QSCI Zone 2 TOP). The School of Computer Engineering and Science at Shanghai University is the first institution listed.
Weed detection is a key technology in precision agriculture, intelligent weeding, and smart farmland management. However, in complex agricultural environments, existing detection methods are prone to false detections and missed detections due to factors such as the highly similar appearances of crops and weeds, severe object occlusion, complex background interference, and significant scale variations, making it difficult to meet practical application needs. To address these challenges, this paper proposes FS-DETR (Frequency-Spatial Detection Transformer), a dual-domain fusion detection Transformer framework that collaboratively models spatial-domain and frequency-domain information to achieve accurate fine-grained weed detection in complex agricultural scenes.
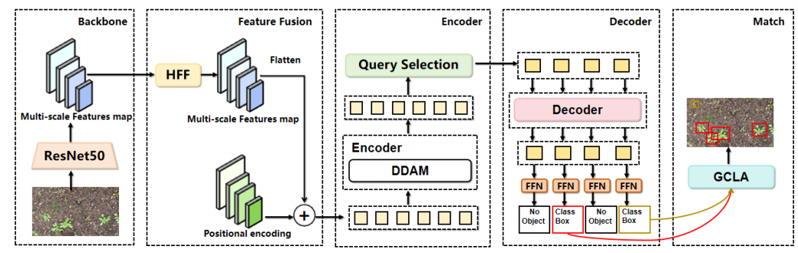
Specifically, this paper proposes a Hybrid Feature Fusion (HFF) module that integrates multi-scale spatial features with high-frequency information in the frequency domain, enhancing the representation of fine-grained texture features and edge information, thereby effectively alleviating detection difficulties caused by crop-weed overlap and complex background interference. Meanwhile, a Dual Domain Attention Mechanism (DDAM) is designed to adaptively fuse frequency-domain attention with deformable attention, fully exploiting spatial structural information and frequency-domain texture information during the encoding stage to improve feature extraction and target discrimination in complex agricultural environments. Furthermore, a Gaussian Distribution-based and Constraint-guided Label Assignment (GCLA) module is constructed to optimize the label matching process for weed and crop targets, improving the quality of supervision and detection accuracy during training.
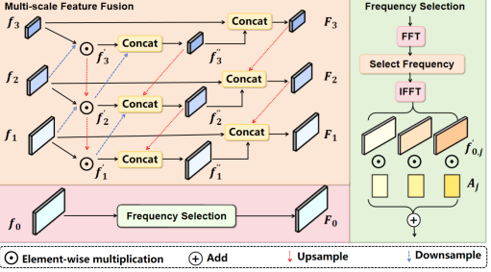
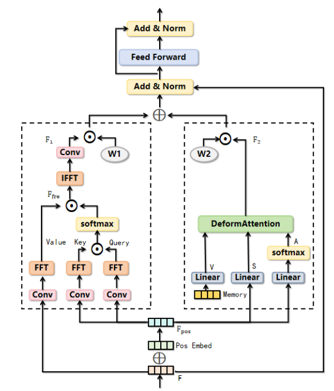
Experimental results on three public agricultural weed datasets, WeedCrop, LincolnBeet, and MH-Weed16, show that FS-DETR achieves excellent performance. Specifically, FS-DETR obtains AP scores of 47.2%, 60.4%, and 32.5% on WeedCrop, LincolnBeet, and MH-Weed16, respectively, improving upon the baseline model by 1.4%, 1.0%, and 0.6%. In addition, for small-object weed detection tasks, FS-DETR improves over the current second-best methods by 1.2% and 0.2%, demonstrating strong fine-grained object detection capability and robustness in complex scenes, and providing a new technical solution for precision weed management in intelligent agriculture.
Essay: A Dual-Domain Detection Transformer for Fine-Grained Weed Detection in Complex Agricultural Scenes
Code: https://github.com/YanSun-github/FS-DETR

Our team published the paper “PDDNet: An End-to-End Object Detection Framework for Real-World Plant Leaf Disease Diagnosis” in Expert Systems with Applications (IF: 7.5, QSCI Zone 1). The School of Computer Engineering and Science at Shanghai University is the first institution listed.
Plant leaf disease detection is an important task in smart agriculture, precision plant protection, and crop health management. However, in real-world agricultural scenarios, leaf lesions are often affected by complex natural backgrounds, multi-scale disease regions, lighting variations, and subtle visual differences between different disease categories. As a result, existing detection methods still face challenges in localization accuracy, classification robustness, and cross-scene generalization. To address this problem, this paper proposes PDDNet, an end-to-end plant leaf disease detection framework that integrates local lesion details with global contextual information through a cascaded encoder-decoder structure, thereby improving disease detection performance in real-world scenarios.
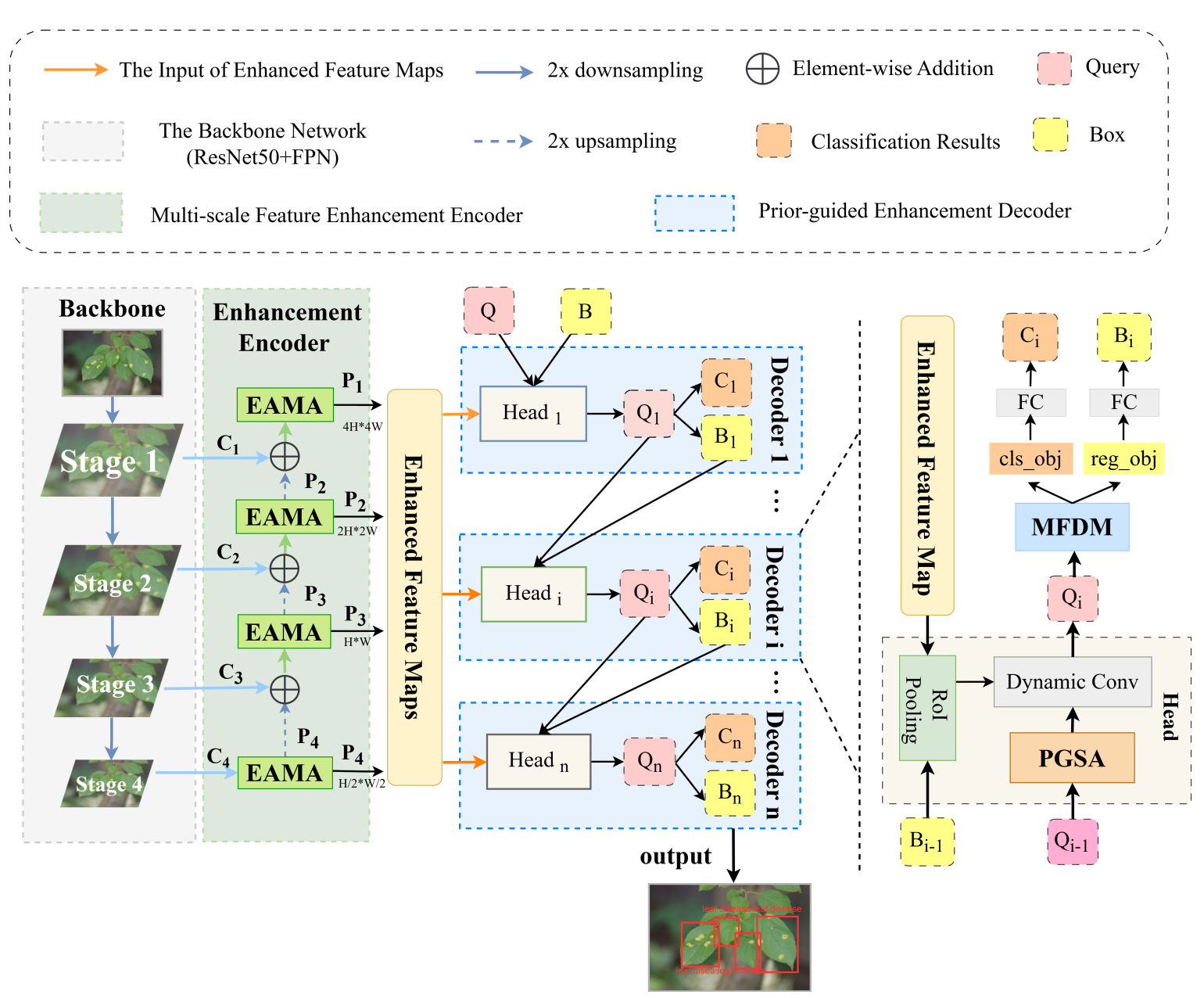
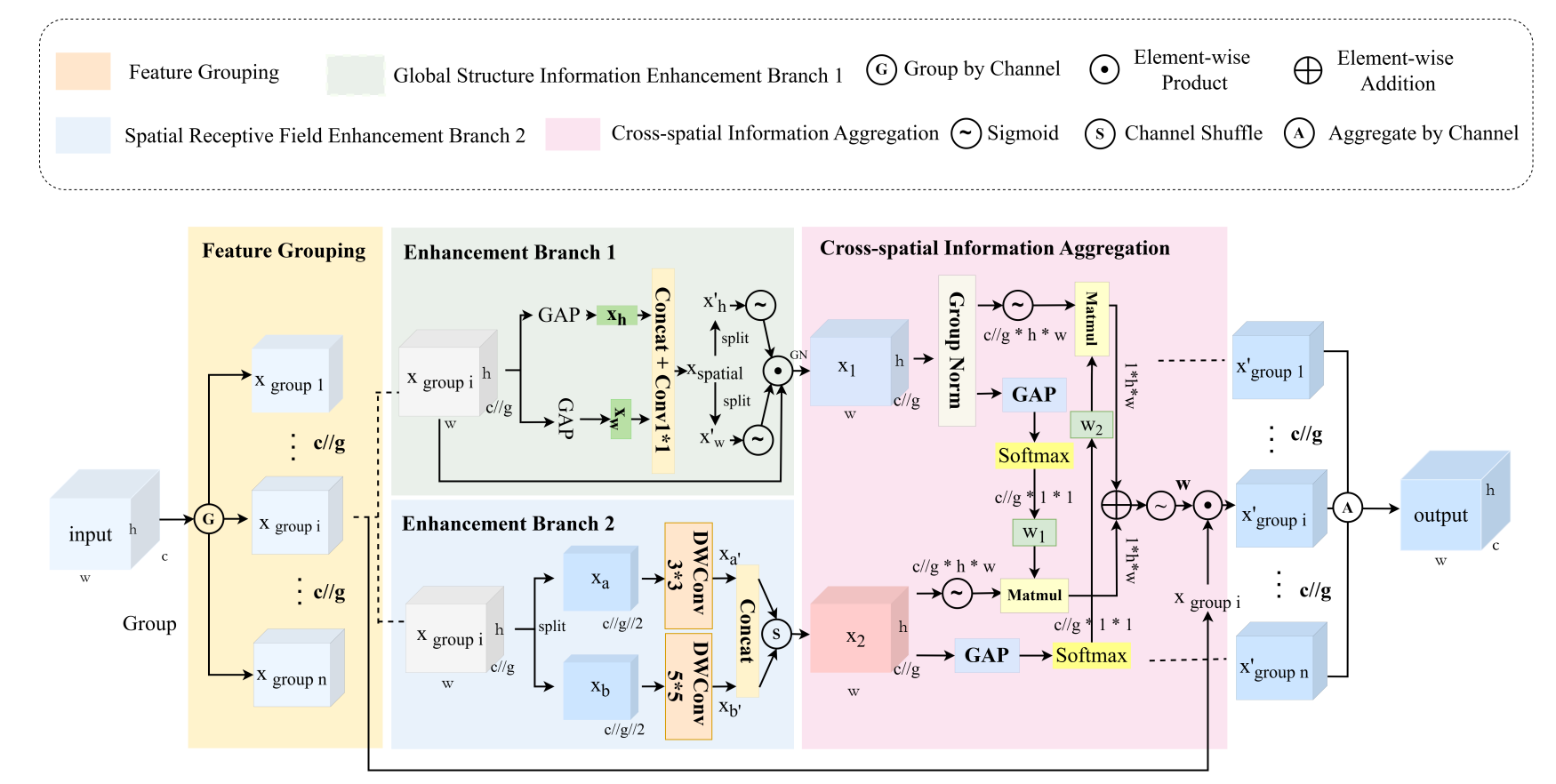
Specifically, we propose an Enhanced Attention-based Multi-scale Aggregation (EAMA) module that strengthens the feature representation capability for lesion regions at different scales through collaborative modeling of spatial attention and channel attention. Meanwhile, a Prior-guided Self-Attention (PGSA) mechanism is introduced to incorporate position priors and IoU geometric relationships into attention computation, enabling the model to focus more effectively on lesion boundaries and morphological structures. Furthermore, this paper designs a Multi-task Feature Decoupling Module (MFDM), which separates classification features from localization features using task-specific dynamic masks, alleviating conflicts between classification and regression tasks. Experimental results on real-world datasets such as PlantDoc and Tomato Leaf Disease show that PDDNet achieves favorable detection performance in complex backgrounds, multi-scale lesion detection, and fine-grained category recognition tasks, providing reliable technical support for automated disease diagnosis in precision agriculture.
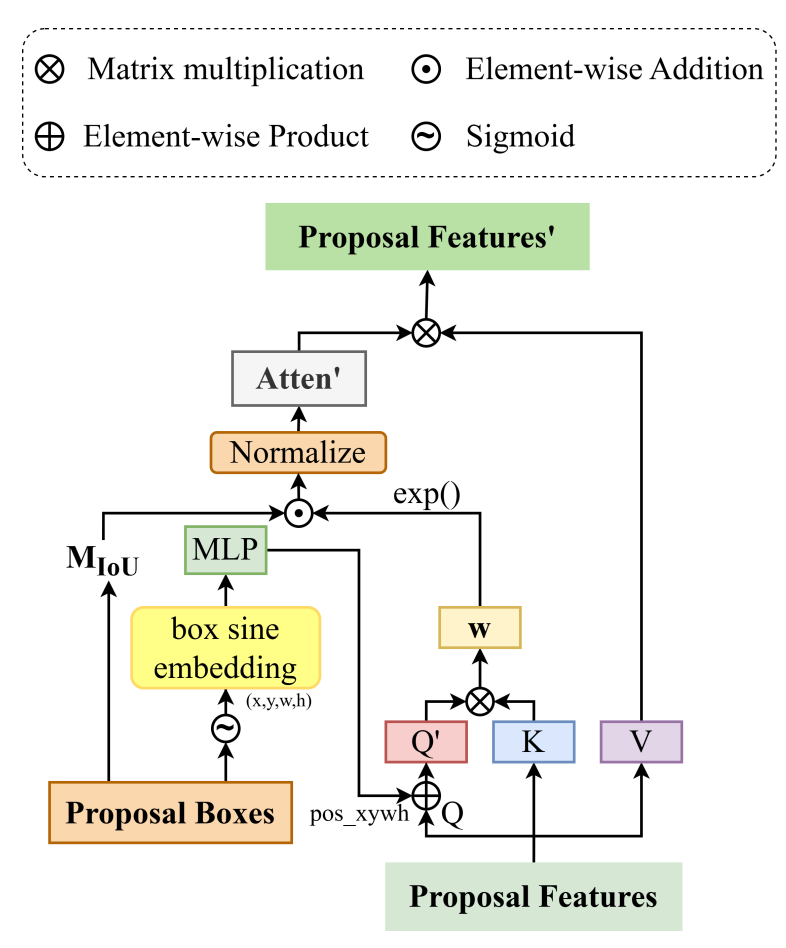
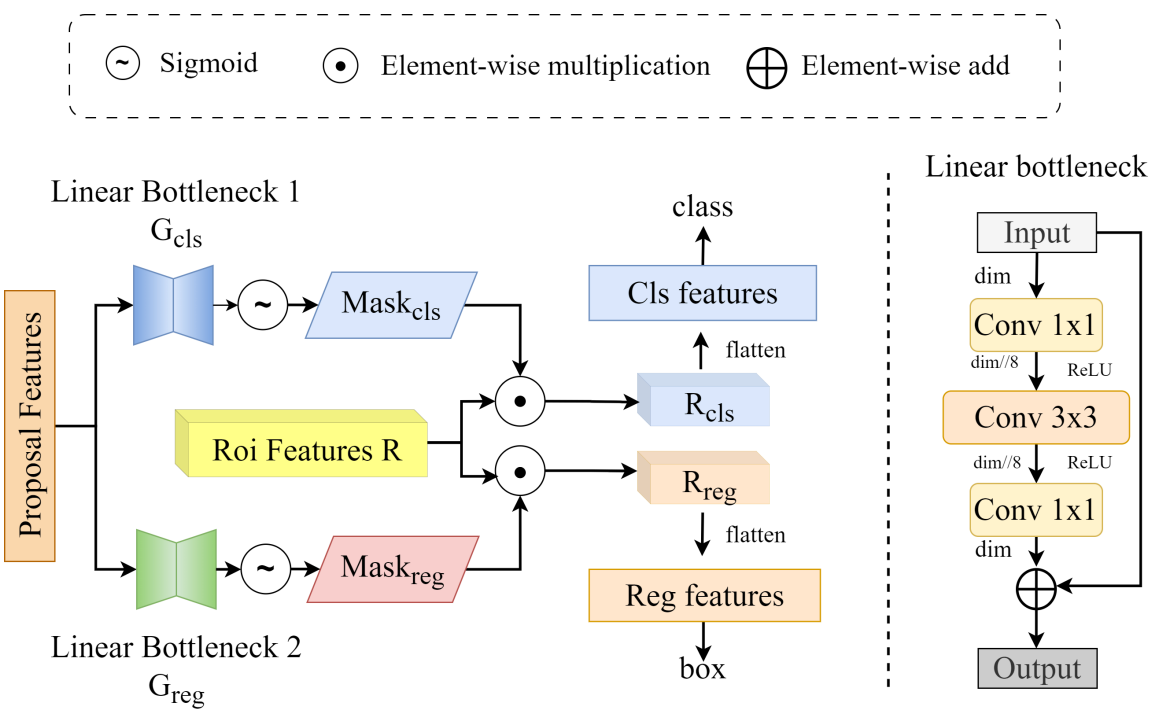
Essay: PDDNet: An End-to-End Object Detection Framework for Real-World Plant Leaf Disease Diagnosis
